create_table, open_table, drop_table, and
rename_table, accept a namespace parameter as input.
Namespace hierarchy
Namespaces are generalizations of catalog specs that give platform developers a clean way to present Lance tables in the structures users expect. The diagram below shows how the hierarchy can go beyond a single level. A namespace can contain a collection of tables, and it can also contain namespaces recursively.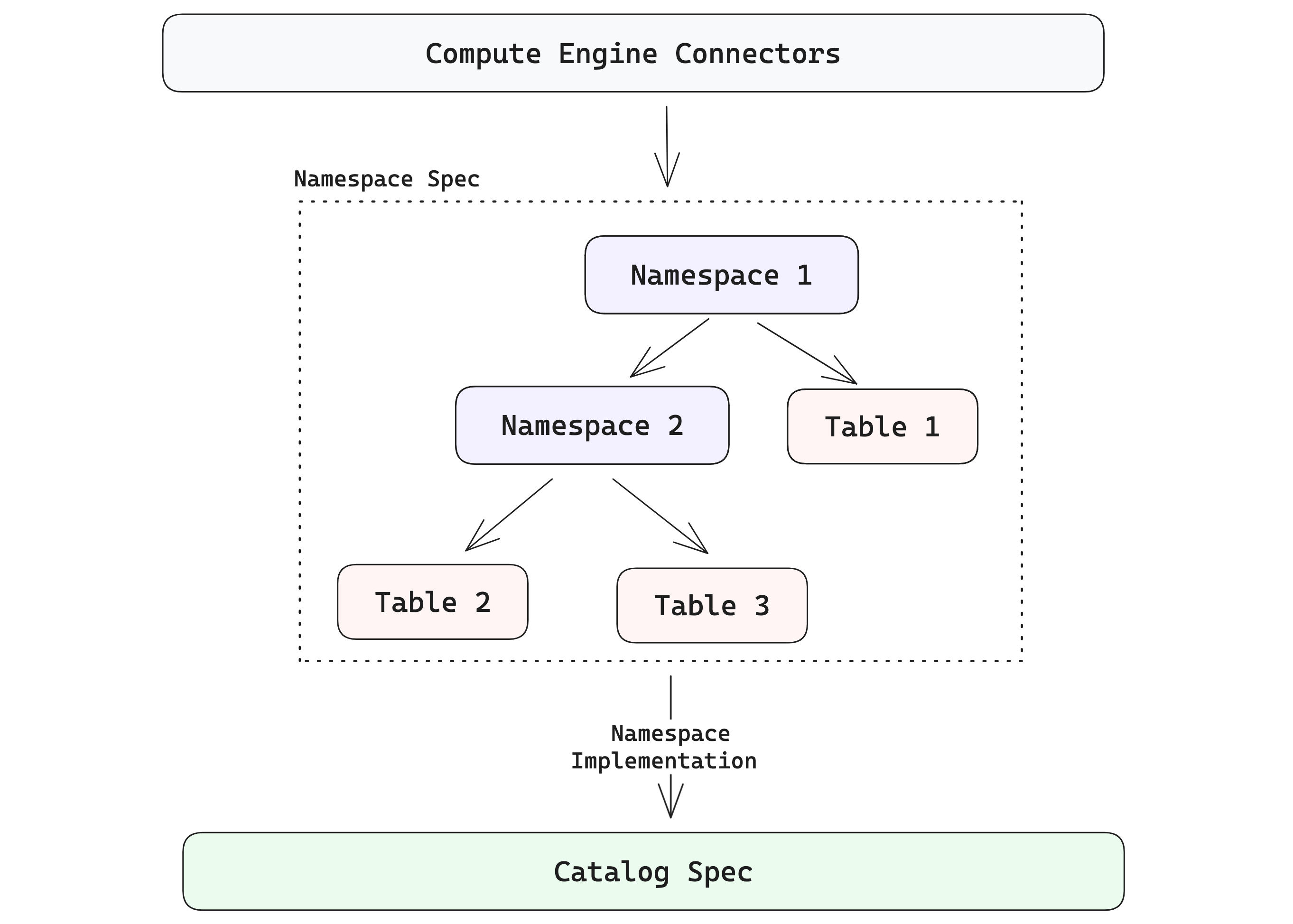
Directory namespaces
The simplest namespace model in LanceDB is a single root namespace, often represented by one directory:data/ directory, where the root namespace is implicit. Connecting to this namespace is as simple as connecting to the catalog root:
Python
lancedb.connect_namespace(...) with the directory namespace implementation:
Python
For simple search use cases in LanceDB OSS, you don’t need to go too deep into namespaces. However, to integrate LanceDB with external catalogs and to use it as a true multimodal lakehouse, understanding the different namespace implementations and how to use them in your organization’s setup is beneficial.
Remote or external catalog namespaces
For remote object stores with central metadata/catalog services (either commercial or open source), use the REST namespace implementation. In LanceDB, this is the same namespace API surface as local directory namespaces, but backed by REST routes (for examplePOST /v1/namespace/{id}/create and GET /v1/namespace/{id}/list) and server-provided table locations.
For authentication, any property prefixed with headers is forwarded as an HTTP header
(for example headers.Authorization becomes Authorization, and headers.X-API-Key becomes X-API-Key).
Python
Best practices
Below, we list some best practices for working with namespaces:- For simple use cases and single, stand-alone applications, the directory-based root namespace is sufficient and requires no special configuration.
- For remote storage locations, introduce explicit namespaces when multiple teams, environments, or domains share the same catalog.
- Treat namespace paths as stable identifiers (for example
"prod/search","staging/recs"). - For maintainability reasons, avoid hard-coding object-store table paths in application code — instead, prefer catalog identifiers + namespaces.